Left panel
Basic functions related to network analysis
Once you decide the details of your own network, the network visualization page will show up for basic analysis purpose as below.
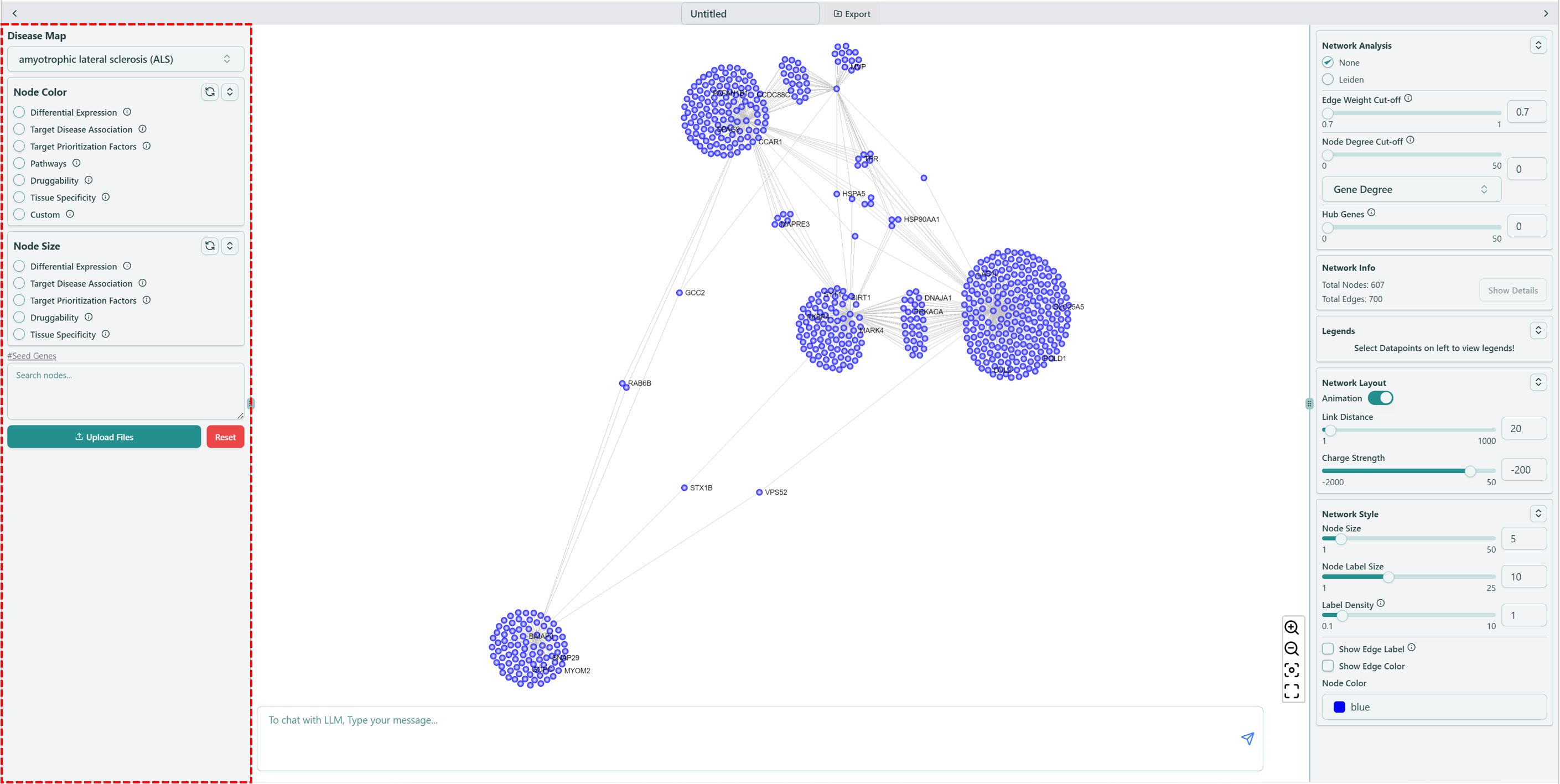 Left panel of network visualization page
Left panel of network visualization page
Before going over the functions on the left panel, you might want to have some basic understandings of the data available in our tool.
Knowledge Base integrated in our tool is build based on disease-dependent data and disease-independent data. Disease-dependent data indicates the data of specific features varies based on different diseases, while disease-independent data indicates the data remains the same once the disease changes.
Disease-dependent data includes Differential Expression and Target Disease Association , while disease-independent data includes Pathways, Druggability and Tissue Specificity. We also call these data types as features.
Disease Map
Sometimes you may want to switch to another disease after generating the network visualization, no need to go back to the Dashboard to change the disease and re-render the network, here is a simple way to do it:
- Locate Disease Map on the top of the left panel and select the disease name that you want to switch to.
- Please note that only the disease-dependent data will change if you switch to another disease.
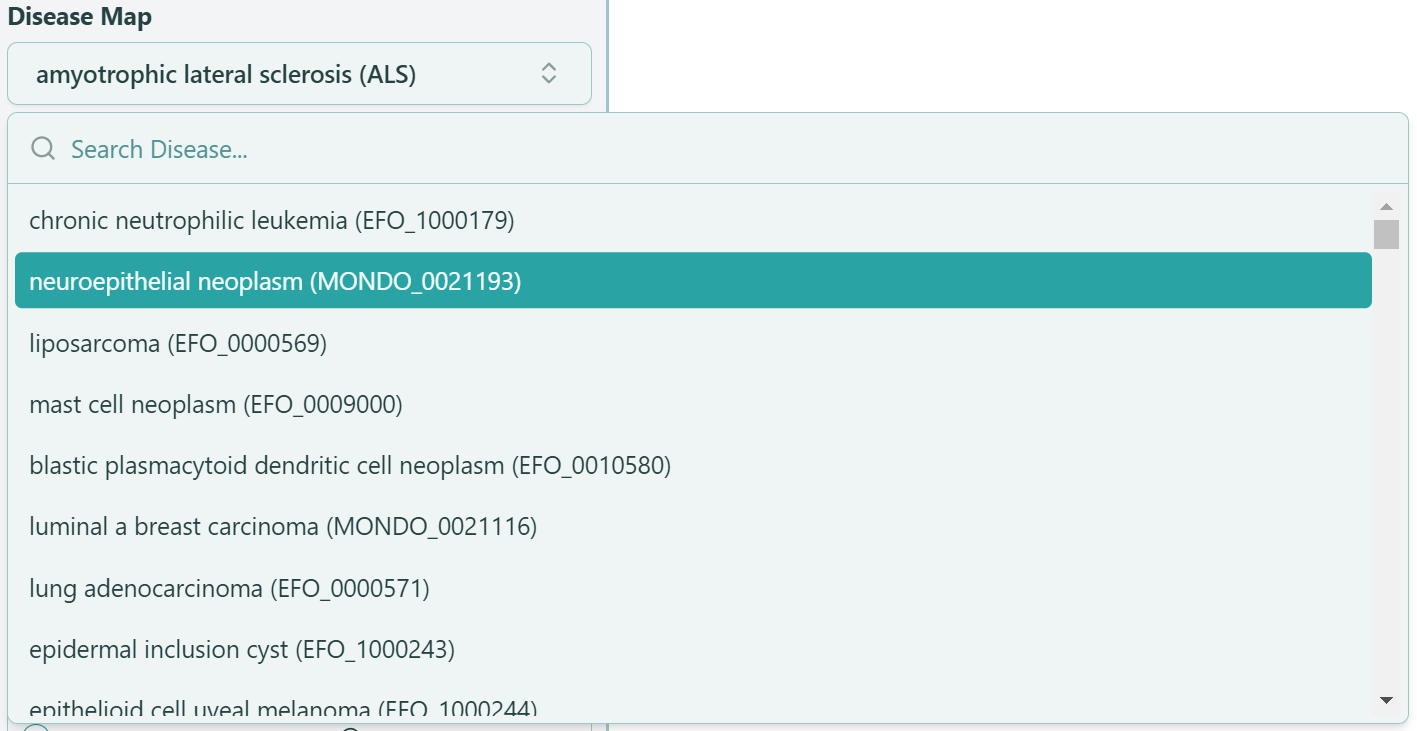 Disease Map
Disease Map
Change Node Color
You can change the node color by selecting different features.
- Choose a feature.
Note: You can hover on the info icon
 to check the explanation.
to check the explanation. - Select the preferred option for that feature in the dropdown list. You can type the keyword in the search bar to help locate the data name.
Note: You can check the Legends section on the Right panel to get the legend of each feature.
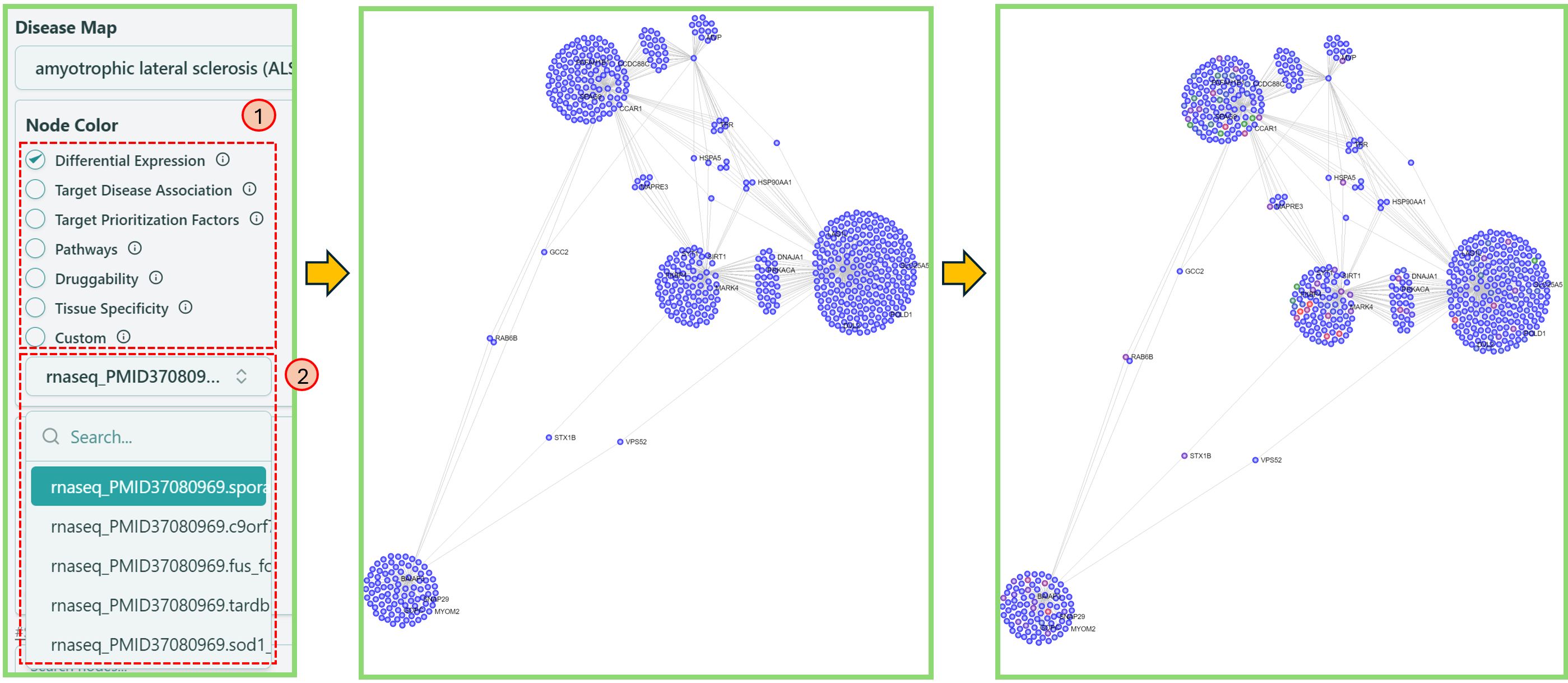 Change node color
Change node color
Change Node Size
You can change the node size by selecting a feature.
- Choose a feature.
Note: You can hover on the info icon
to check the explanation. - Select the preferred data for that feature in the dropdown list. You can type the keyword in the search bar to help locate the data name.
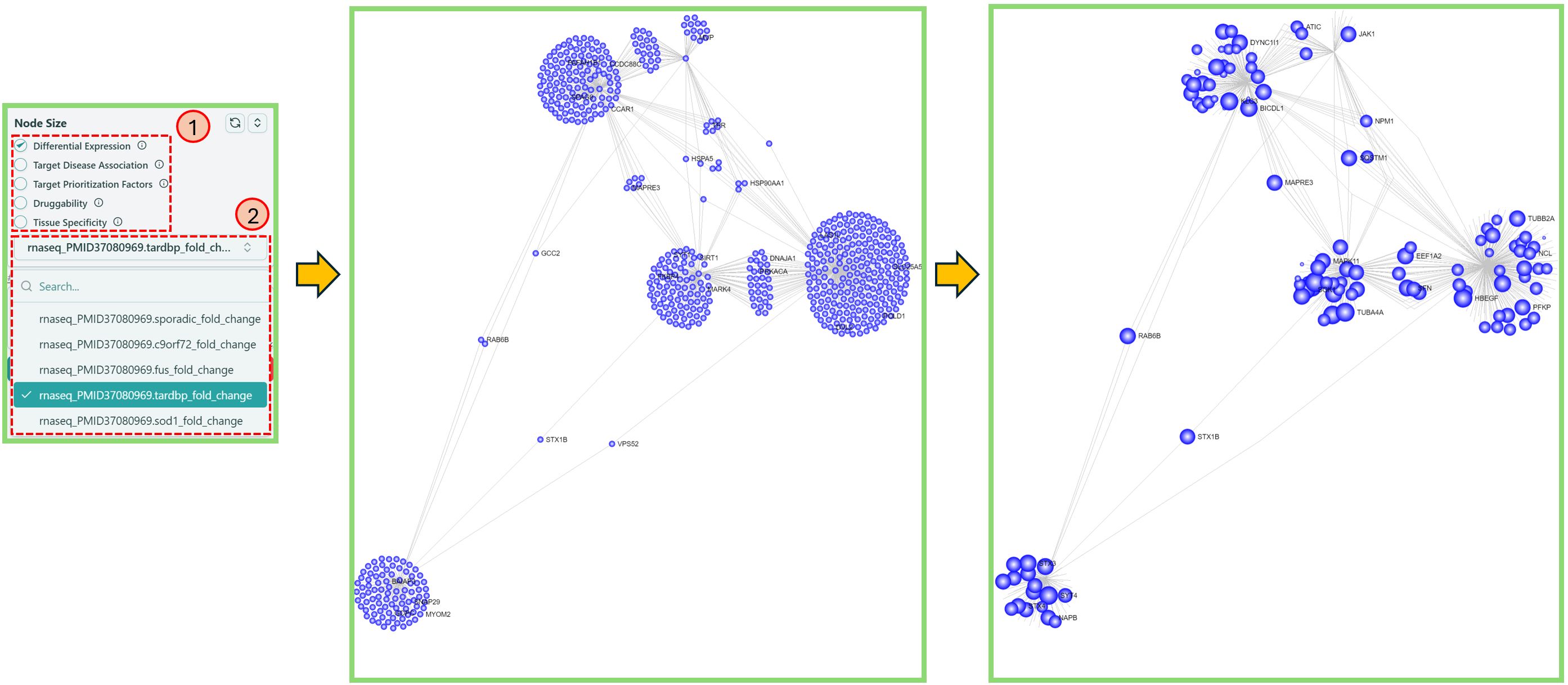 Change node size
Change node size
We provide less features in Node Size section simply because the feature Pathways is binary features — either a gene exists in a pathway or it does not exist. However, to change the node size in a network, we need consistent data instead of the binary data.
Combination of both Node Color and Node Size Change
Node color and node size can be both changed at the same time to highlight the corresponding genes, making them clearer.
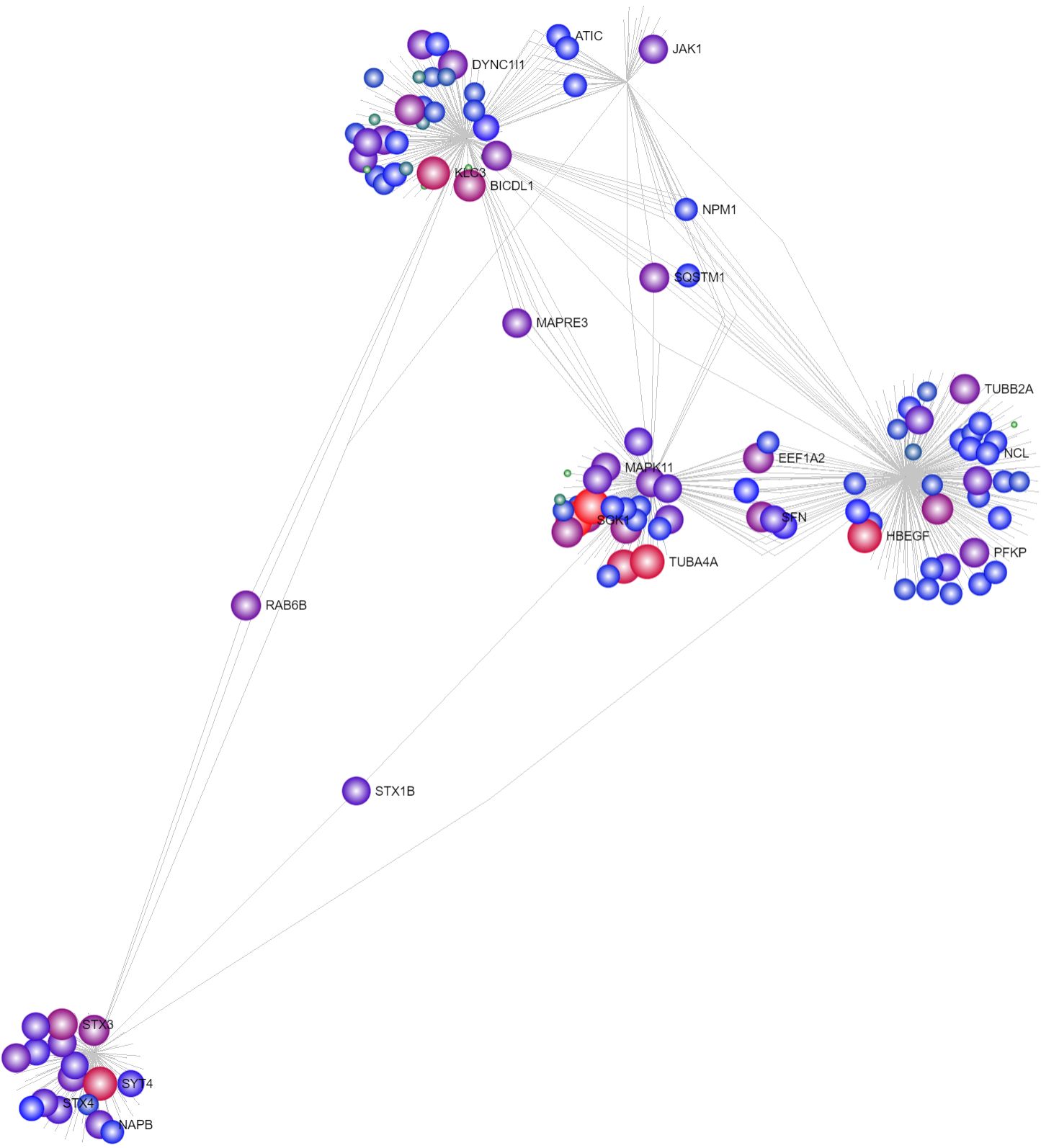 Change both node color and node size
Change both node color and node size
Custom Search
You can find nodes in the network.
- Locate the search box.
- Enter the gene names or Ensemble IDs into the search box.
Note: To find seed genes, simply click
#Seed Genesabove the search box. - The nodes you are looking for will be highlighted in the network.
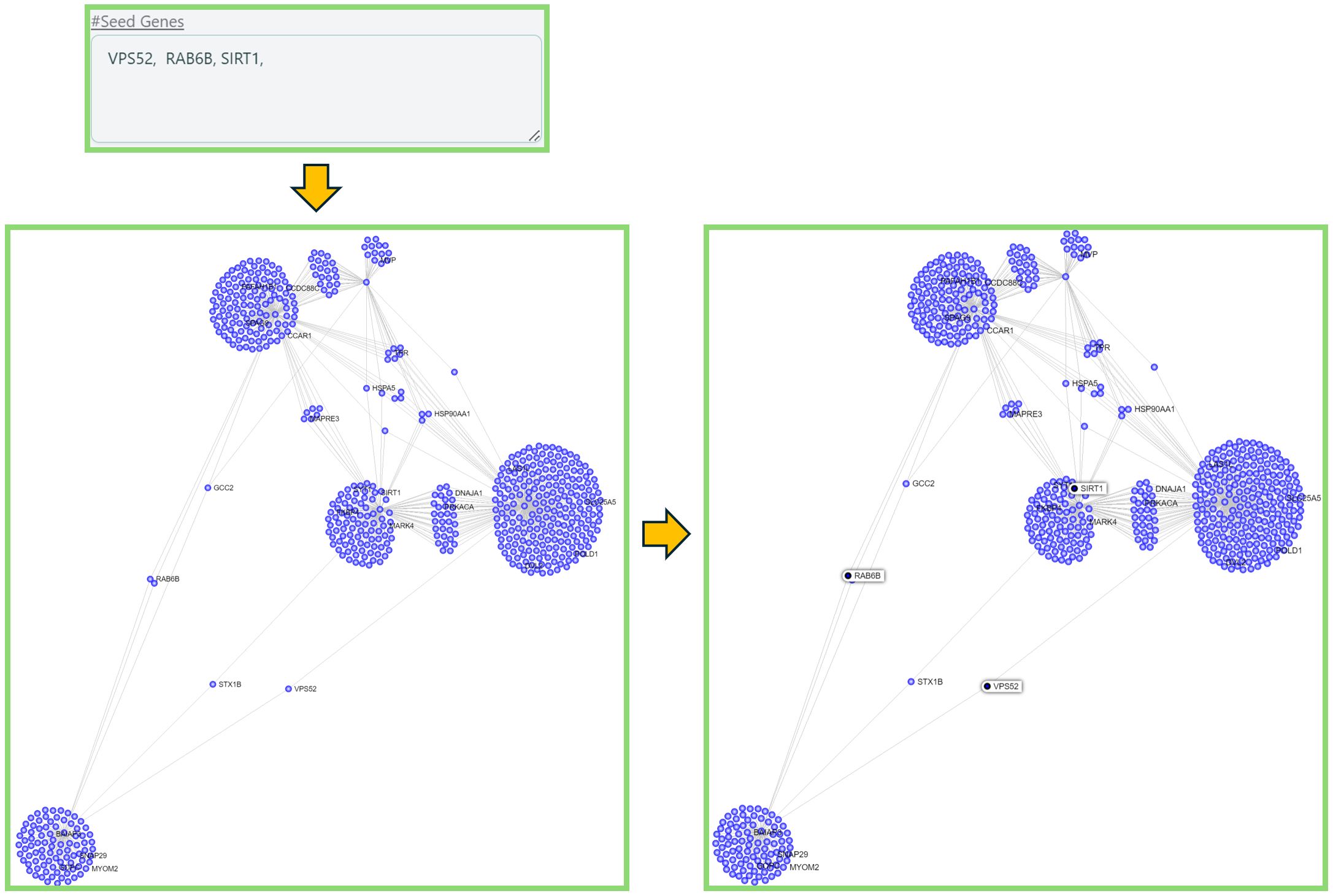 Custom search
Custom search
Custom Upload
You can upload your own customized data to analyze the network, instead of using the existing data. Here is a help video.
- Upload a CSV file with your own data, please refer to the File Format below.
- Click Submit.
- Locate Node Color and/or Node Size section and select the corresponding uploaded feature name.
- Select the column name of your customized data.
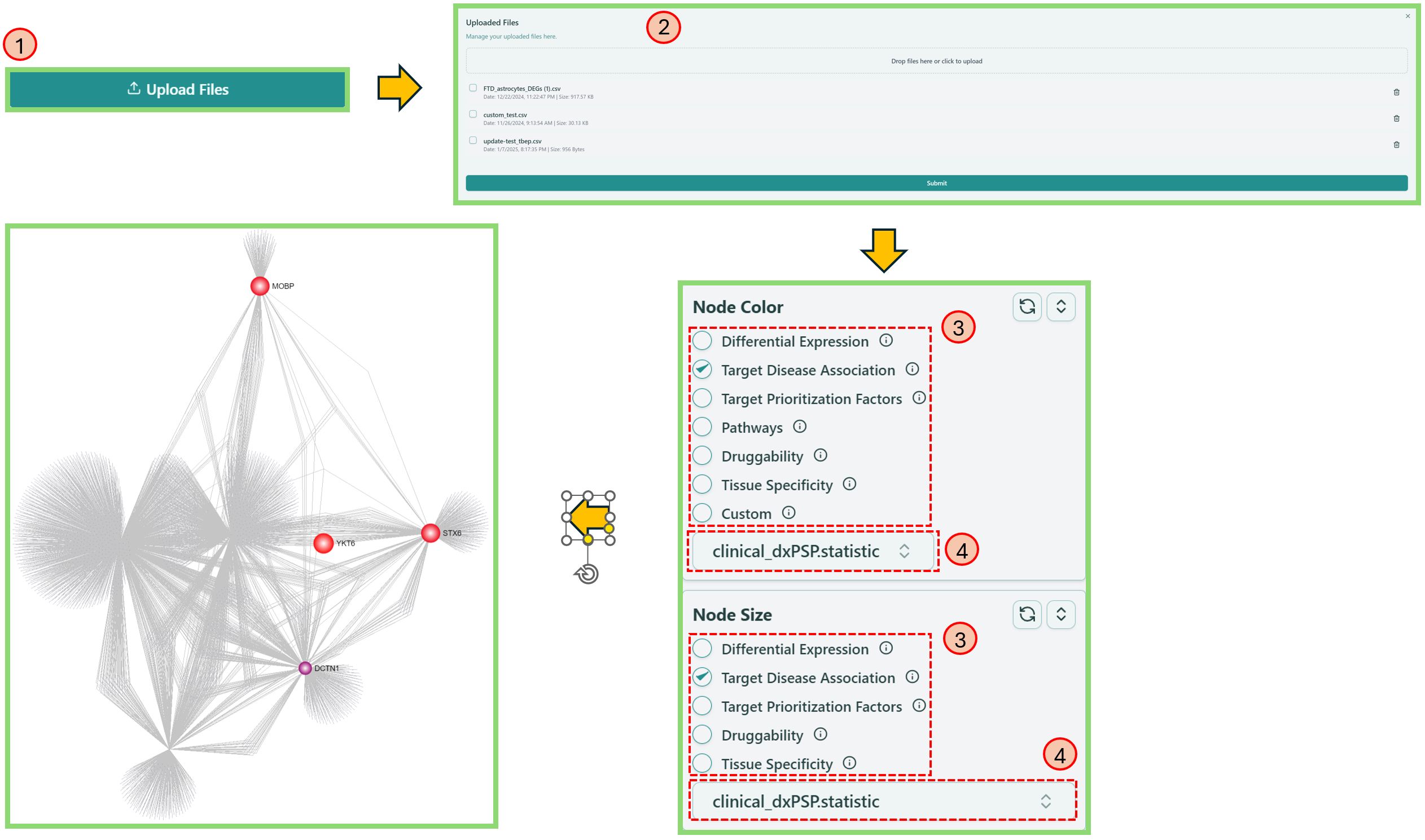 Custom upload
Custom upload
File Format
- The table below elaborates the naming convention, and the value ranges for all the supported features (data types).
- “Custom” data type is for customized color purpose. For example, if you find all the features do not fit your needs, you can create your own “customized feature” and color them by yourself.
| Data Type | Column Naming Convention | Value range |
|---|---|---|
| Differential Expression | DEG_CustomName | [-Inf, +Inf] |
| Target Disease Association | OpenTargets_CustomName | [0, 1] |
| Target Prioritization Factors | OT_Prioritization_CustomName | [-1, 1] |
| Pathway | Pathway_CustomName | Binary (0/1) |
| Druggability | Druggability_CustomName | [0, 1] |
| Tissue Specificity | TE_CustomName | [0, +Inf] |
| Custom | Custom_Color_CustomName | Any hex color code or CSS color name, see list here ↗ |
- The CSV file below provides an example of what the real file looks like.
- The first column must be either gene name or Ensembl id (column name doesn’t matter)
- The prefix of columns is case-insensitive
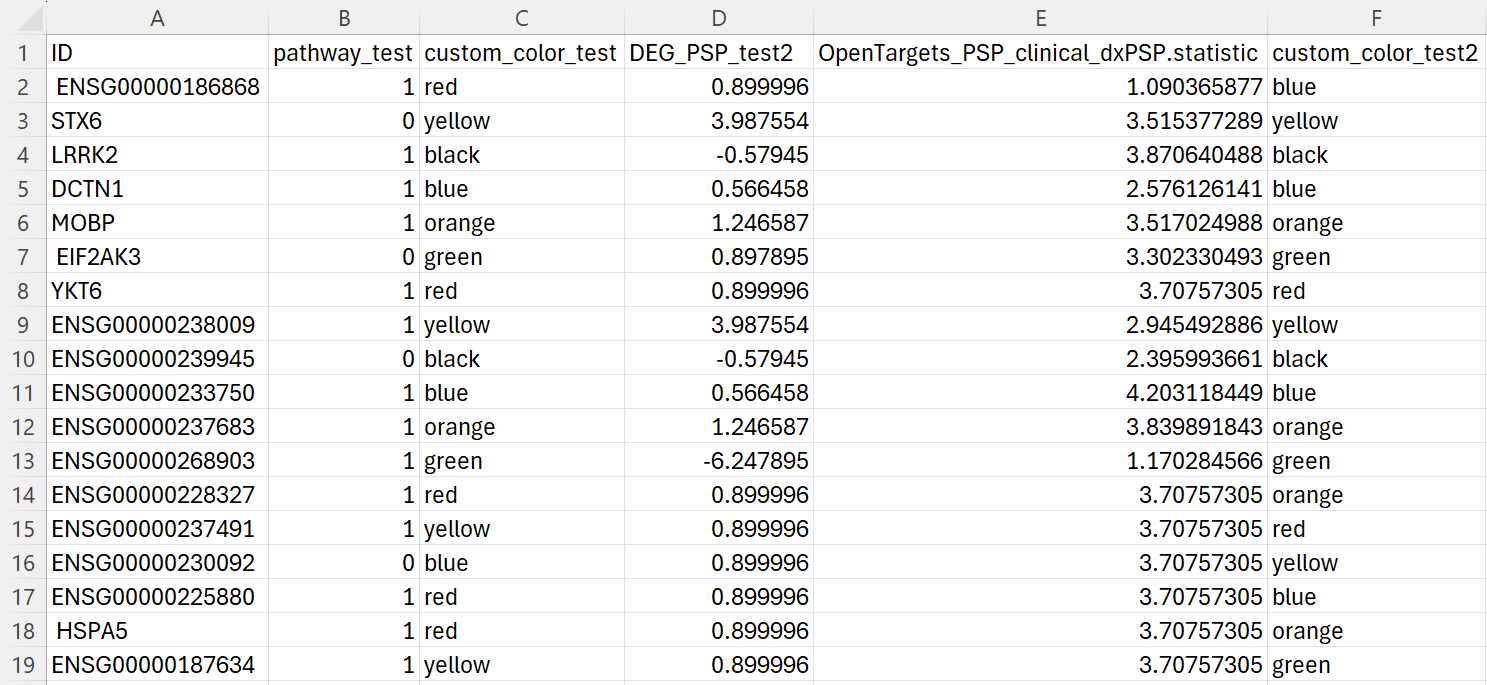 Example of a customized CSV file
Example of a customized CSV file